

过去几年,我们累计管理和维护了 1,000 多个 HubSpot 门户。无论行业还是规模如何,大多数 HubSpot 门户最终都会出现相似的问题。团队并非没有认真维护,但数据管理中的一些问题却总是一再出现——而这些,也恰恰是业内很少有人真正会拿出来讨论的话题。
大多数关于 HubSpot 数据管理的文章都会告诉你应该使用哪些功能:合并重复记录、设置必填字段、建立几个工作流……这些做法当然没有问题。然而,六个月之后,账户里的数据往往又变得杂乱无章。
真正值得思考的,其实不是应该使用哪些功能,而是为什么数据总会再次变乱,以及数据质量下降究竟会带来怎样的代价。比如,会议上的报表没人真正相信;营销预算持续投入到无效联系人身上;潜在客户的数据混乱到无法进行有效分析……这些问题最终都会影响企业的业务判断和决策。
接下来,我们将结合实际项目经验,分享几乎每个 HubSpot 门户都会遇到的几个典型问题。相信其中不少,你都会觉得似曾相识。
什么才是真正的数据管理?
数据管理的基础工作,你或许已经很熟悉。例如,合并重复的联系人和公司、为不同对象设置必填属性、尽量使用下拉菜单和固定字段类型,而不是允许自由输入,以及通过工作流自动处理重复性的修正工作。
HubSpot 也提供了相应的工具,包括重复记录管理(Dupli,
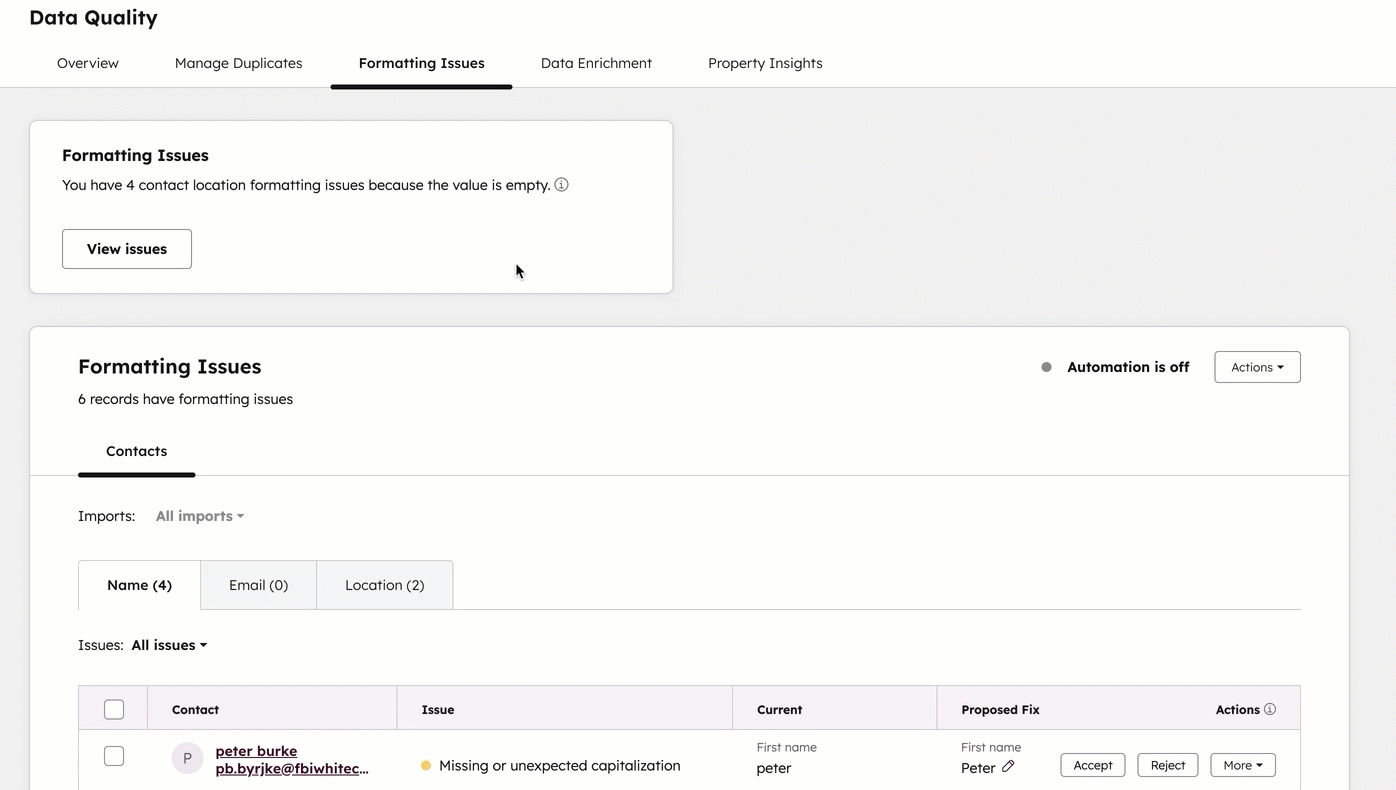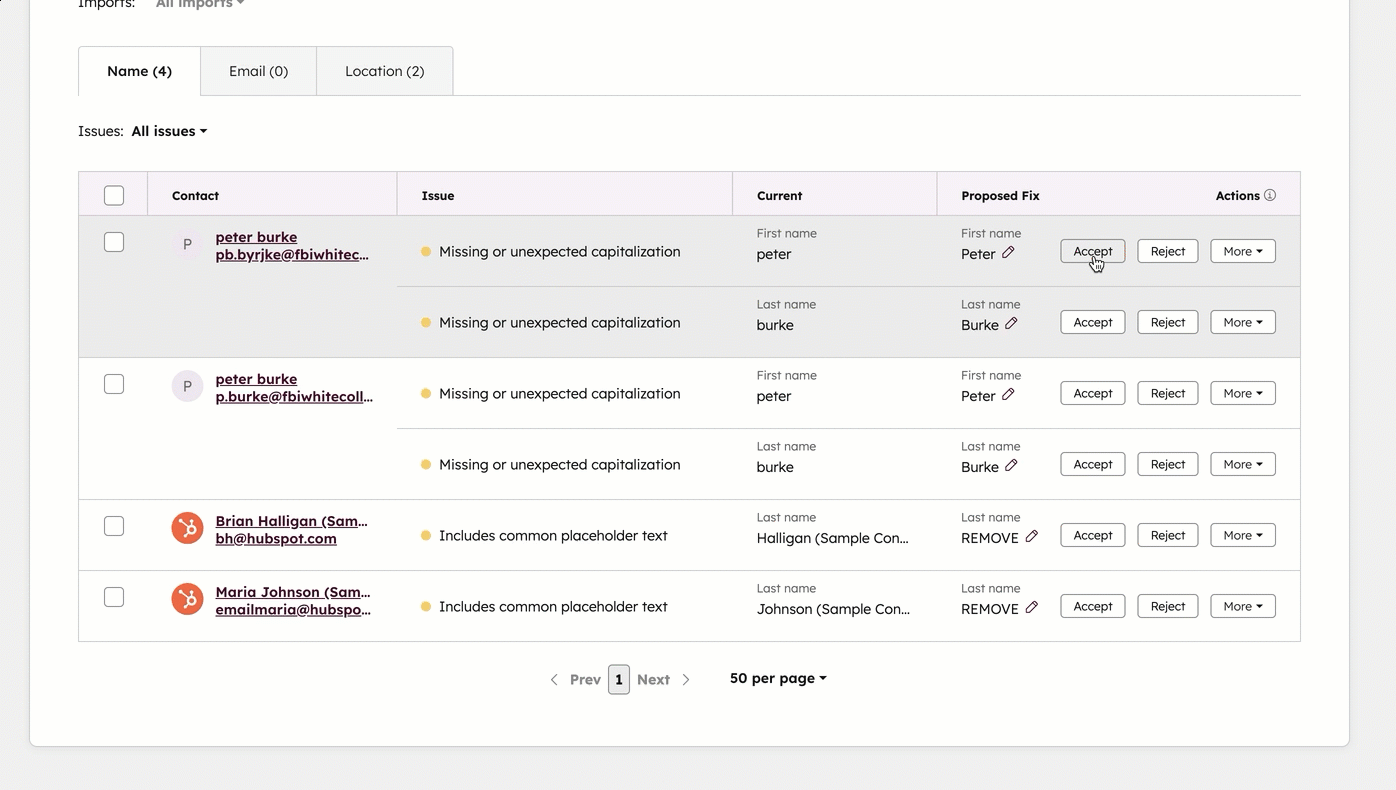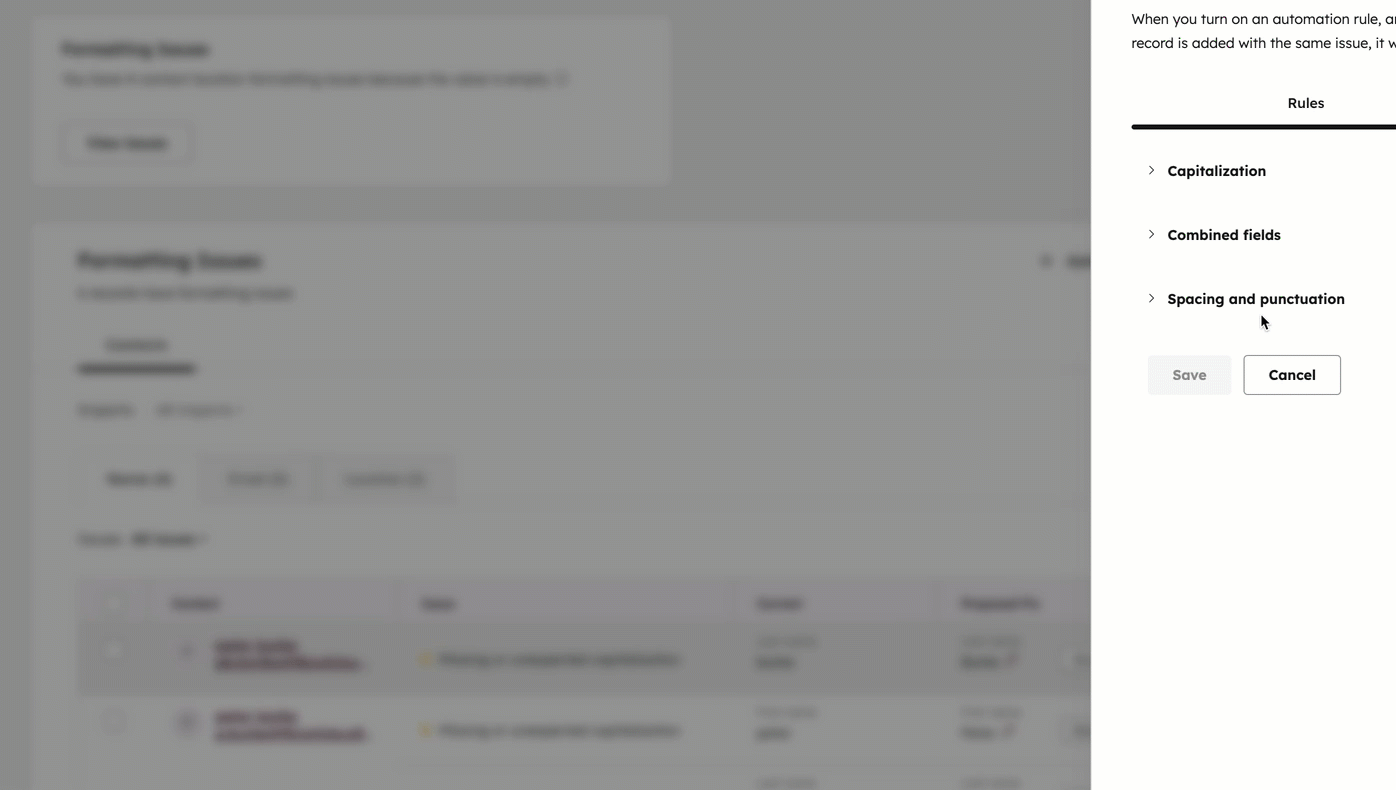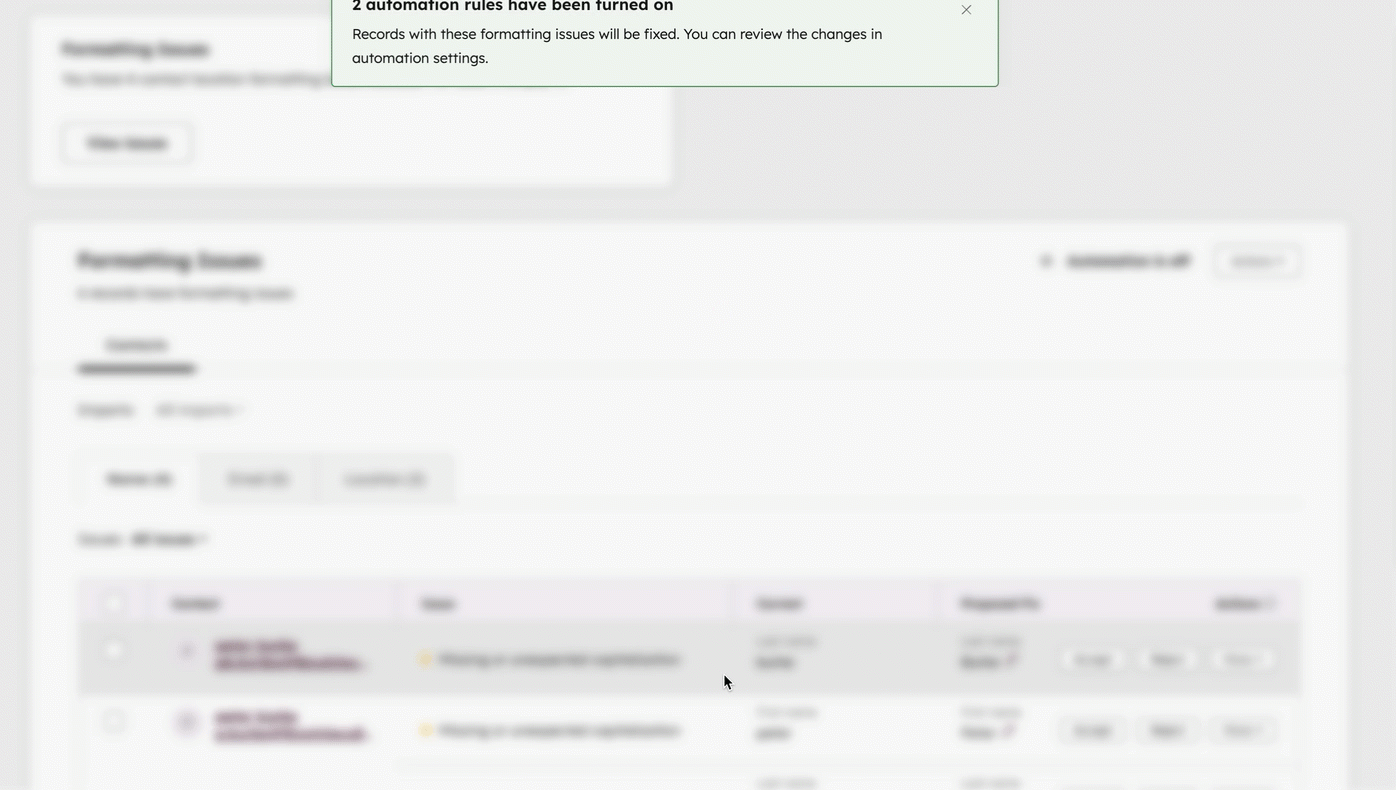
HubSpot 数据质量中心可集中查看重复记录、格式错误及属性质量情况。来源:HubSpot Knowledge Base
这些都是数据管理不可或缺的基础工作。但仅做到这些,还远远不够。因为真正的问题,并不是没有人知道如何合并重复记录,而是每天都有新的数据不断流入,却没有人持续确保这些数据始终保持规范和准确。也正因如此,真正的数据管理,并不是完成一次配置就结束,而是从这里才真正开始。
七个最常见的问题
单独来看,这些问题似乎都不算严重。但当它们长期累积时,就会让整个 HubSpot 门户的数据质量不断下降,最终导致团队对系统失去信任。
数百个属性字段,没人知道它们的用途
在几乎所有运行超过两年的 HubSpot 门户中,我们都会发现一个共同现象:系统里存在数百个属性(Properties)。其中相当一部分早已没有任何用途——既没有用于列表,也没有用于工作流,更没有出现在任何报表中。
这并不是因为团队管理疏忽。每一次新的营销活动、每接入一个新的工具,甚至团队临时提出的一项业务需求,都可能新增一个属性字段。但这些字段却很少有人敢删除,因为没有人能够确定,它是否仍在某个地方被引用。于是,属性越来越多,系统也越来越复杂。
对于营销负责人来说,真正的问题并不是字段数量,而是数据标准变得越来越模糊。当同一项信息对应着三个不同的字段时,没有人能够确定,究竟哪个字段才是真正可信的数据来源。报表引用了错误的字段,客户分群越来越不精准,甚至同一场会议上,不同的人制作出的报表都会得出不同的数据结果。
解决办法其实并不复杂。定期检查现有属性,利用 HubSpot 提供的工具识别哪些字段已经闲置、哪些字段存在重复或功能重叠。对于不再使用或含义重复的字段,应及时进行合并或清理;而新增字段,则需要建立统一且清晰的命名规范。不过,仅仅整理一次远远不够。因为新的字段还会不断出现。只有将属性管理纳入固定的日常维护流程,才能真正避免问题再次发生。
没有人真正对数据负责
当我们询问一家企业:"谁负责数据质量?" 大多数时候,都得不到一个明确的答案。营销团队认为联系人应该由销售团队维护;销售团队则认为系统本身已经能够自动处理这些数据。结果就是,没有任何人真正对数据负责。
这也是为什么,许多企业虽然制定了数据管理规范,却始终无法真正落实到日常工作中。每个人都有自己的维护方式,最终也就没有人真正把数据维护好。没有明确的数据责任人,再完善的 HubSpot 门户,也会随着时间推移逐渐失去数据质量。
有效的解决方式,是建立清晰的数据责任机制。明确由某位成员或某个团队负责整体数据质量,同时规定每一个字段应以哪个系统作为唯一可信的数据来源(Single Source of Truth)。然而,很多企业内部并没有这样的岗位,不是因为不重视,而是既缺乏足够的人力,也缺少深入的 HubSpot 管理经验。在这种情况下,将数据管理交由专业的外部合作伙伴持续维护,往往是更现实、也更高效的选择。
生命周期阶段(Lifecycle Stage)与实际情况脱节
生命周期阶段(Lifecycle Stage)的作用,是反映联系人在整个客户旅程中所处的位置,从潜在客户(Lead)一路发展为正式客户(Customer)。然而在实际使用过程中,这项数据往往并不准确。已经成交的客户仍停留在 Lead 阶段;多年前的潜在客户却突然变成了 Customer;更令人头疼的是,没有人知道这些变化究竟是如何发生的。
造成这种情况的原因,通常包括人工修改以及彼此冲突的工作流。此外,还有一个很多用户并不了解的细节:当你在 HubSpot 中合并两个联系人时,系统会保留生命周期中更靠后的那个阶段。也就是说,如果你将一位刚获取的新 Lead 与一条历史 Customer 记录合并,即使实际情况并非如此,系统仍会自动将该联系人保留为 Customer,而不会给出任何提示。
对于数据分析而言,这类问题的影响是致命的。漏斗分析将无法真实反映客户转化情况,营销与销售之间的线索交接也会变得混乱,因为生命周期阶段已经失去了可信度。任何希望准确区分 MQL(Marketing Qualified Lead,营销合格线索)与 SQL(Sales Qualified Lead,销售合格线索)的企业,都必须首先确保生命周期阶段本身准确、统一且可信。
解决这一问题的关键,在于为每个生命周期阶段制定清晰的定义,通过自动化确保阶段按照统一规则更新,并定期检查各阶段的数据分布是否符合实际业务情况。
重复记录总是反复出现
几乎每家企业都曾经清理过重复记录,而且几乎每一次,几个月后它们又会重新出现。原因很简单:重复记录并不是一次性产生的问题,而是在不断出现。它们可能来自填写了不同邮箱地址的表单、数据导入,或是缺乏正确匹配规则的系统集成。仅仅进行一次合并,并不能解决问题,因为新的重复记录仍在持续产生。
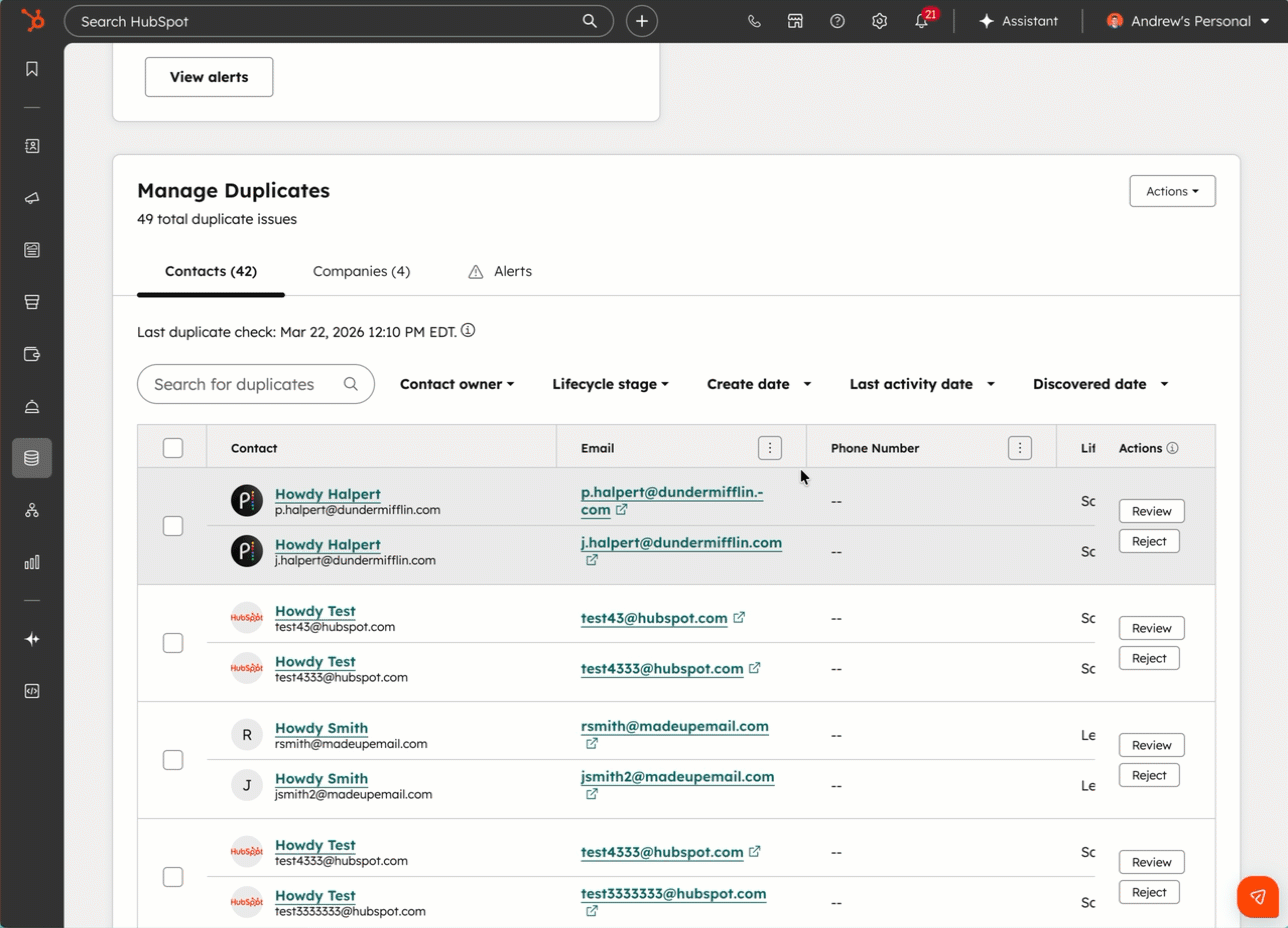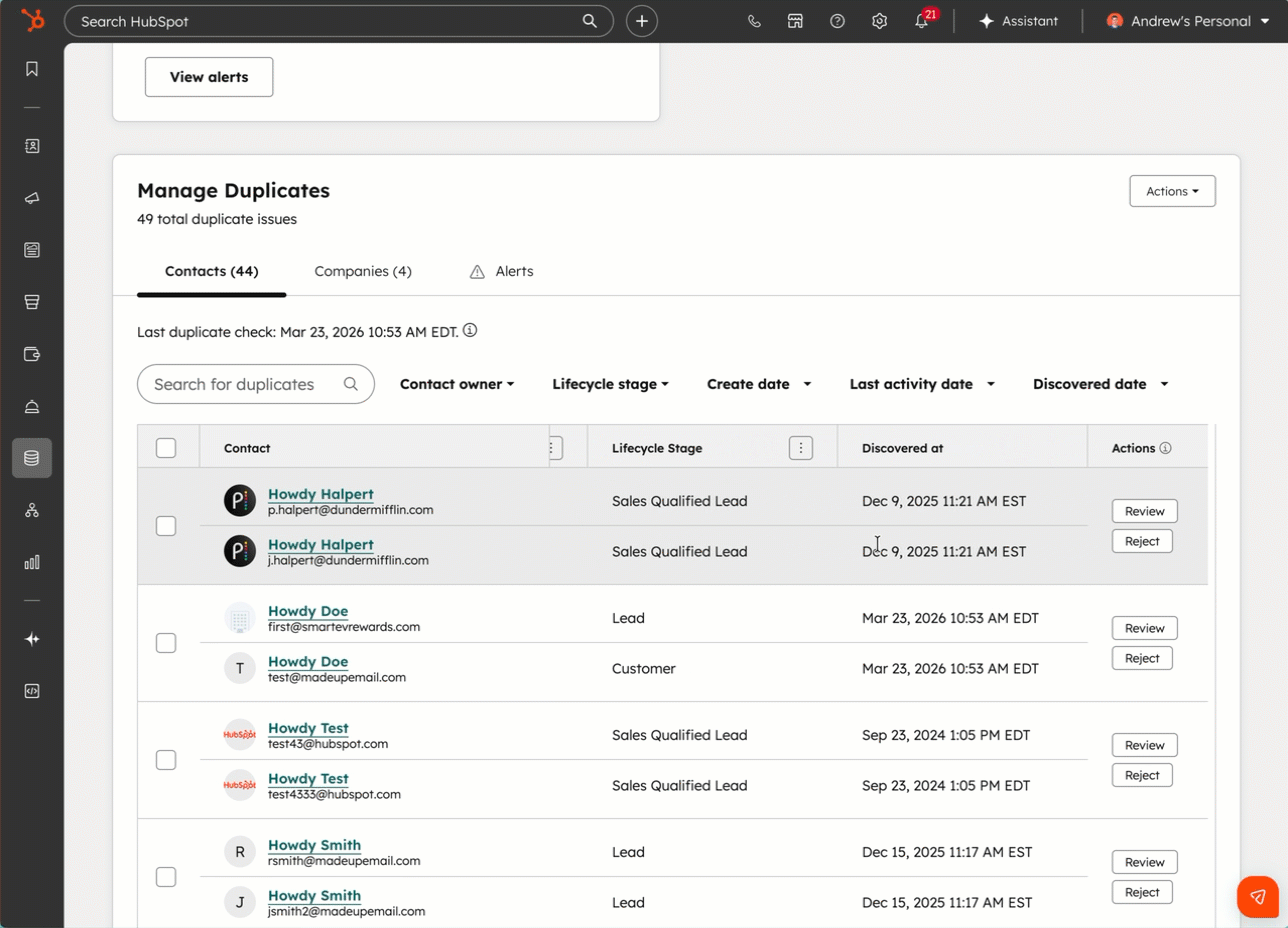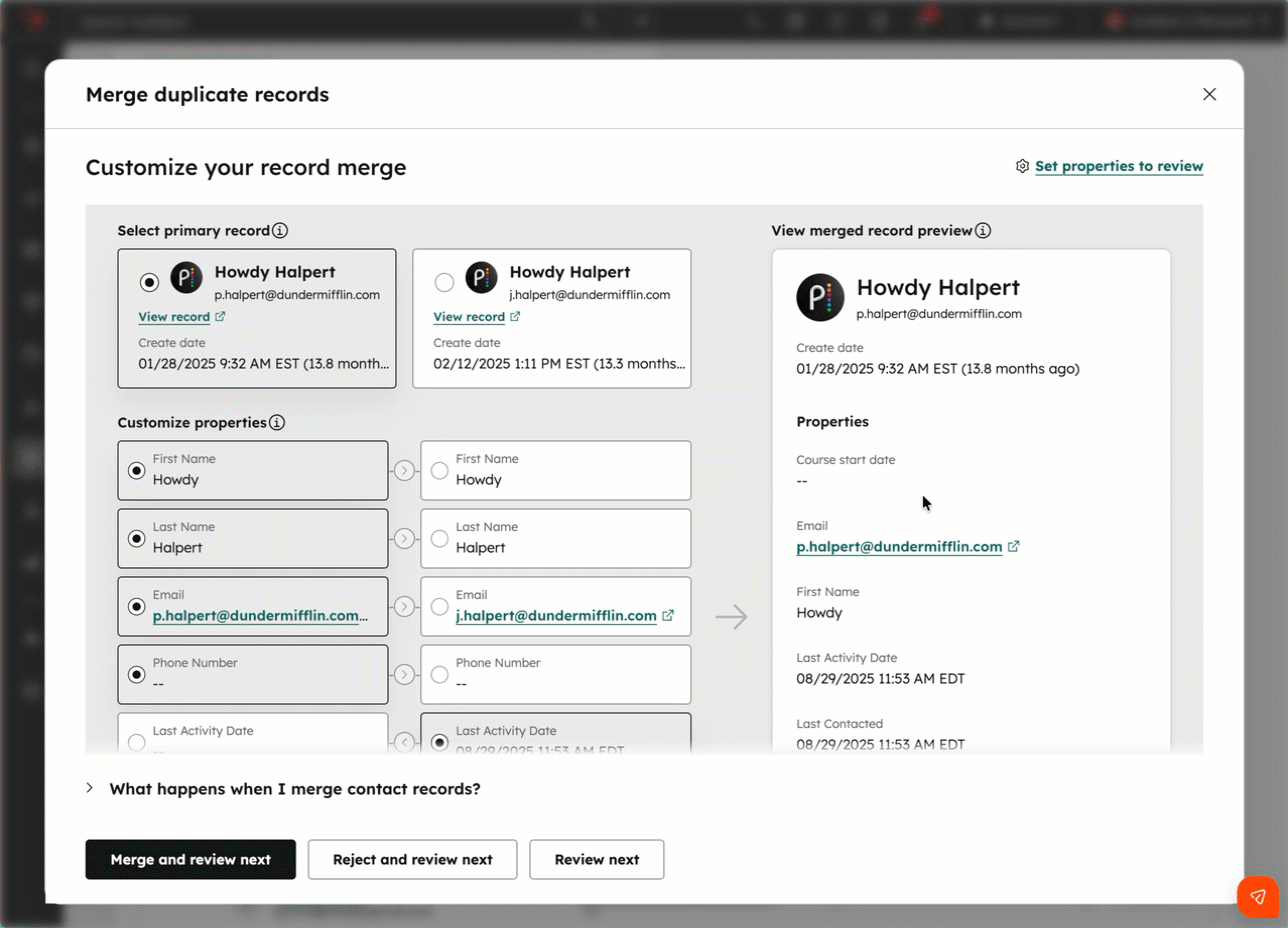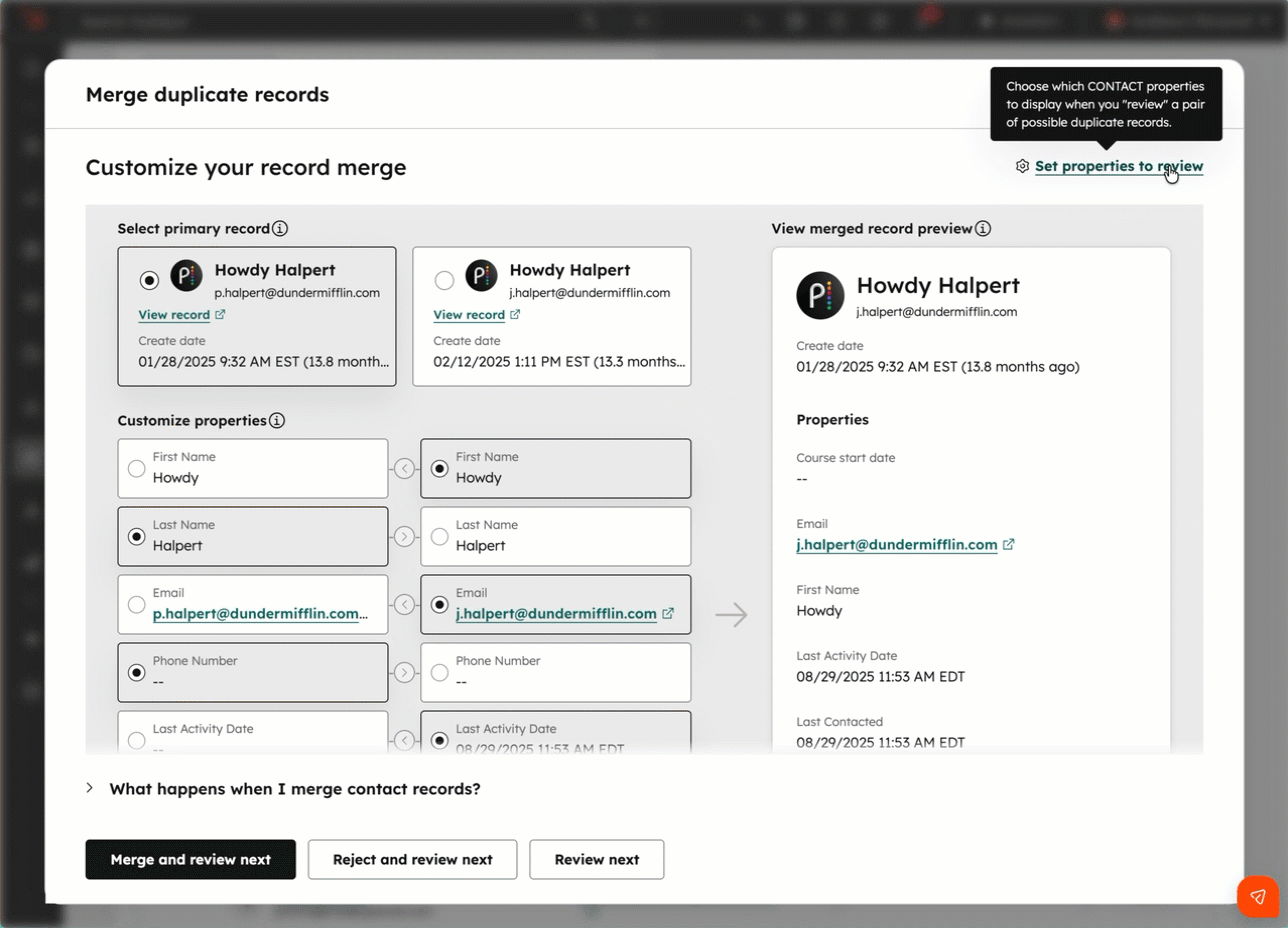
关于合并重复记录,还有两个细节值得特别注意。
第一,在 HubSpot 中,合并操作不可撤销。一旦完成合并,没有“撤销”按钮,就连 HubSpot 官方支持团队也无法恢复。
第二,对于大多数属性而言,最终保留的并不一定是主记录(Primary Record)的数据,而是最近一次更新的值。这意味着,如果在没有仔细核对数据的情况下匆忙完成合并,很可能会让错误或质量较低的数据覆盖掉原本准确的数据。
当 HubSpot 与 Salesforce 等其他系统进行集成时,情况会更加复杂。如果联系人在另一套系统中被合并,那么在历史记录同步到保留记录之前,该联系人就有可能已经从 HubSpot 中消失,从而造成归因数据缺失,而这一问题往往不会被及时发现。
真正有效的做法,是从源头减少重复记录的产生。配置好表单和系统集成,让它们能够识别已有联系人,而不是不断创建新记录;建立明确的合并规则,并将重复记录管理作为一项固定的日常工作,而不是一次性的清理任务。
你一直在为无法触达的联系人付费
这一点几乎每个月都在让大多数企业默默增加成本,却很少有人意识到。
在 HubSpot 中,你付费的并不是所有联系人,而是营销联系人(Marketing Contacts)。然而,通过表单、数据导入或系统集成新增的联系人,默认都会被创建为营销联系人。如果之后某位联系人取消了邮件订阅,或邮箱地址已经失效,HubSpot 的确不会再向其发送邮件,但并不会自动将其降级为非营销联系人。这意味着,即便这些联系人已经无法触达,你仍然需要继续为他们支付费用。
当系统中积累了上千条这样的无效联系人时,每年很容易白白多花数千欧元,却得不到任何实际价值。
这个问题只需进行两项调整即可解决。第一,让所有新联系人默认以非营销联系人的身份进入系统,而不是自动成为营销联系人。第二,通过工作流在联系人连续 180 天未活跃后,自动将其降级为非营销联系人。在许多 HubSpot 门户中,仅完成这两项优化,就足以将 HubSpot 的使用成本降低 30% 至 50%。不过,真正需要注意的是时间节点。HubSpot 会在每月第一天统计计费联系人数量,因此,本月完成的调整要到下个月才会生效。如果希望节省费用,应在月底之前完成清理,而不是等到新月份开始之后。
会议上的报表,没有人真正相信
你或许遇到过这样的情况:同一场会议中,两个人展示的是同一个 HubSpot 门户的数据,结果却完全不同;或者归因报表把大量业绩归功于一个你明知道并非真正来源的渠道。这通常并不是报表本身的问题,几乎总是底层数据出了问题。
其中一个很容易被忽视的原因,就是 HubSpot 表单。默认情况下,HubSpot 表单会直接覆盖已有字段的值,并没有“仅当字段为空时才填写”的设置。因此,当一位已经存在于系统中的潜在客户再次提交另一份表单时,新填写的信息会直接覆盖原有数据,最初的来源信息也随之丢失。
还有一种情况更加棘手。如果两个人使用的是同一个浏览器,其中一人提交过 HubSpot 表单,之后另一人也在同一浏览器中提交表单;或者有人点击了一封他人转发给自己的营销邮件,HubSpot 都有可能将新的提交记录关联到之前那位联系人,并覆盖其原有数据。原因在于,HubSpot 的关联依据是浏览器 Cookie,而不是联系人本身。
这意味着,营销团队最关心的问题反而变得无法回答:究竟是哪一个渠道真正带来了收入? 一旦来源数据失去可信度,即使企业拥有完整的 CRM 系统,最终也只能依赖经验和直觉来做营销决策。
有效的做法,是保护那些关键字段。例如,首次来源(Original Source)只记录一次,之后不再被覆盖;重要字段只有在为空时才允许更新;同时,应认真检查表单配置,而不是直接使用默认设置。
一次“大扫除”,解决不了真正的问题
很多企业都会每年集中开展一次数据清理。团队花上一整天整理数据、修正问题,但几个月之后,HubSpot 门户又恢复到了原来的混乱状态。原因其实很简单:新的数据每天都在不断进入系统,旧的数据也在持续失效。面对这样持续发生的变化,一次性的清理行动根本无法长期解决问题。
除此之外,还有一点很少有人会提及:HubSpot 真正高效的数据管理功能,大多集中在更高等级的许可证中。通过工作流自动统一数据格式,以及使用数据质量中心(Data Quality Command Center),都需要 Operations Hub Professional 或以上版本;而基于 AI 的重复记录识别,则需要 Enterprise 版本。其中一项尤为实用的能力,是不仅能够批量修正现有数据格式,还可以在每一条新数据进入系统时自动完成格式校验与修正。现实中,很多企业一边依靠人工反复整理数据,一边却没有使用相应版本所提供的自动化工具;也有一些企业已经购买了更高级别的许可证,却从未真正启用这些功能。
无论是哪一种情况,最终都会带来同样的结果:投入了大量时间和精力,数据依旧不断变得混乱,而企业也在持续为没有得到充分利用的功能支付费用。
数据管理不是一个项目,而是一项持续运营工作
把前面提到的这些问题放在一起看,你会发现一个共同点:没有任何一个问题能够通过一次性处理彻底解决。数据会不断“老化”——员工会离职,公司会搬迁,邮箱地址也会失效。根据 MarketingSherpa 的数据,B2B 联系人数据平均每月会衰减约 2.1%,相当于每年约 22.5%。在技术等变化较快的行业,这一比例甚至更高,而平均每位 B2B 联系人大约每 18 个月就会更换一次工作。因此,无论你曾经做过多么彻底的数据清理,数据本身都在持续贬值。
这不仅仅是数据卫生(Data Hygiene)的问题,更直接关系到企业营收。Gartner 估算,数据质量不佳平均每年会给企业带来 1,290 万美元的损失。虽然这一数字主要受到大型企业的影响,但对于一家中型企业而言,损失通常也达到每年数十万美元。Harvard Business Review 则指出,数据质量问题可能导致企业损失 15% 至 25% 的收入。而在 Validity 发布的《2025 CRM 数据管理现状》(State of CRM Data Management 2025)报告中,超过三分之一的受访企业表示,他们曾因数据质量问题直接损失收入。换句话说,数据是一项资产,而一旦停止维护,它的价值就会持续下降。
因此,真正应该思考的问题,并不是如何把 HubSpot 门户清理干净一次,而是谁负责持续保持它的数据质量,以及通过怎样的机制去维护它。这也正是大多数企业内部方案最容易失败的地方——并非能力不足,而是没有人真正承担这项责任,也没有足够的时间持续投入其中。
持续运营,才是真正的答案。相比一次性的清理项目,更重要的是每个月持续维护数据、工作流、权限设置以及合规要求,让 HubSpot 门户始终保持良好的运行状态,而营销和销售团队也能够专注于自己的核心工作。
瑞士市场的特殊情况
最后,再谈谈合规,因为对于瑞士企业而言,这是一个尤为重要的话题。保持数据整洁,不仅关系到报表的准确性,也是法律合规的基本要求。企业必须能够可靠地处理退订(Opt-out)请求,严格遵守数据删除期限,并对数据访问进行可追溯的记录。根据修订后的《瑞士联邦数据保护法》(revDSG),企业需要满足一系列特定要求,而这些要求并不完全等同于 GDPR。
如果企业同时在瑞士和欧盟开展业务,就必须同时满足 revDSG 与 GDPR 两套法规。在实际操作中,这意味着同意管理(Consent)、数据删除期限以及访问权限等设置,都需要兼顾两项法规的要求。而这一切的前提,都是拥有规范且准确的数据,因为只有数据本身保持正确,删除期限和退订状态才能得到可靠执行。
常见问题
HubSpot 中的数据管理是什么?
在 HubSpot 中,数据管理是指所有确保门户数据准确、完整且保持一致的工作,包括合并重复记录、维护属性和生命周期阶段、修正数据格式错误,以及监控各项系统集成的数据质量。
HubSpot 数据应该多久维护一次?
理想情况下,应将数据维护作为一项持续性的工作,而不是每年集中清理一次。每月进行一次简短的检查,处理重复记录和明显的数据错误;每季度再开展一次更全面的审查,能够帮助 HubSpot 门户长期保持整洁和有序。一次性的清理往往难以持久,因为新的数据始终在不断流入。
哪些 HubSpot 功能可以帮助进行数据管理?需要什么许可证?
重复记录管理功能适用于所有许可证版本。通过工作流实现自动格式规范,以及使用数据质量中心(Data Quality Command Center),则需要 Operations Hub Professional;基于 AI 的重复记录识别功能则需要 Enterprise。企业应根据自身希望实现的自动化程度,选择合适的许可证版本。
数据质量差会带来哪些成本?
数据质量问题既会产生直接成本,也会带来间接损失。直接成本包括持续为已经无法发送营销邮件的营销联系人付费;间接成本则包括错误的报表分析、营销预算浪费,以及基于不准确数据做出的业务决策。Harvard Business Review 指出,数据质量问题可能导致企业损失 15% 至 25% 的收入;Gartner 则估算,企业平均每年因此造成 1,290 万美元的损失。
如何防止重复记录再次出现?
关键在于从源头减少重复记录的产生。应配置好表单和系统集成,使其能够识别已有联系人,而不是不断创建新的记录;同时建立明确的合并规则,并将重复记录管理纳入固定的数据维护流程,而不是作为一次性的清理工作。
HubSpot 能否满足 revDSG 和 GDPR 的合规要求?
可以。实现合规的关键包括:通过双重确认(Double Opt-in)获取有效授权、严格执行数据删除期限,以及保留可追溯的数据访问日志。如果企业同时在瑞士和欧盟开展业务,就需要同时满足 revDSG 与 GDPR 两套法规的要求。
与其反复清理,不如持续保持数据整洁
如果没有人持续维护,HubSpot 门户中的数据就会随着时间推移越来越不准确,最终发展到会议上的任何人都不再相信系统中的数据。避免这种情况,并不需要一次规模更大的数据清理,而是需要建立一套可靠的持续运营机制。作为拥有 1,000 多个项目经验的 HubSpot Diamond Partner,我们每天都在帮助企业维护 HubSpot 门户,也清楚知道哪些做法能够长期保持数据健康,哪些问题又会在不知不觉中侵蚀数据质量。
想让专业团队帮你全面检查 HubSpot 数据?
数据质量并不是一个做完就结束的项目,而是一项需要持续运营的工作,而这正是 HubSpot Admin-as-a-Service 所提供的价值。我们以固定的服务费用、明确的响应时效,以及专属团队的持续支持,帮助企业每个月维护 HubSpot 门户,让数据始终保持规范、可靠。
如果你想了解这项服务如何应用到你的 HubSpot 门户,我们很乐意安排一次 30 分钟的沟通,带你详细了解我们的工作方式。







